
简介
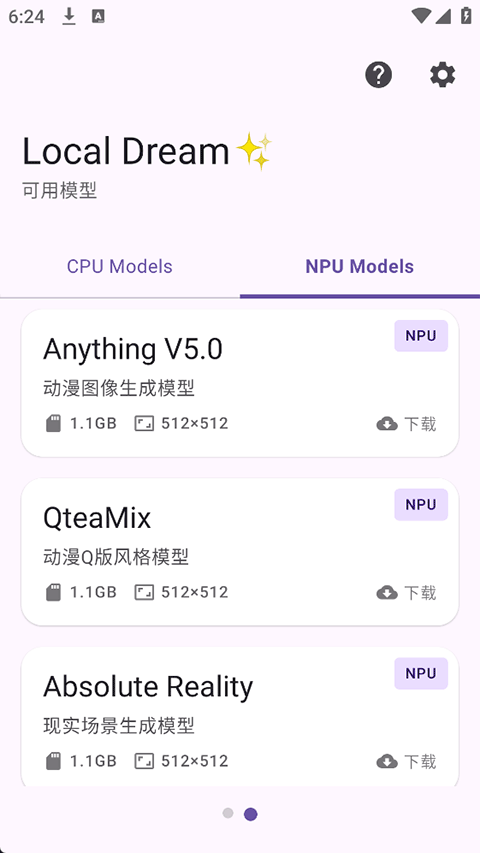
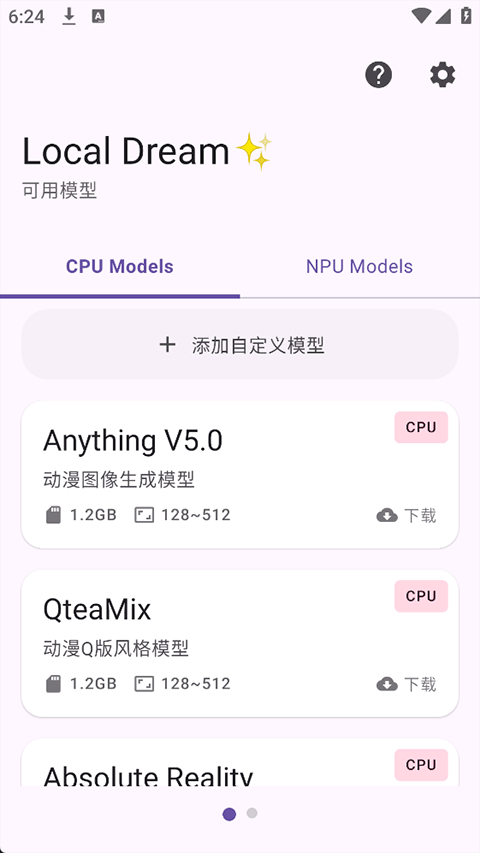
LocalDream 是一款真正为移动端打造的本地化 AI 绘画神器,无需联网、不传数据,只需输入几个关键词,几秒内即可在手机上生成高质量图像。无论你是想在通勤路上随手创作概念图,还是深夜灵感迸发急需将脑洞可视化,它都能快速响应。应用针对不同性能设备智能适配双推理引擎:旗舰机型可调用高通骁龙 NPU 硬件加速,出图快至 3–4 秒;中低端设备则通过 CPU/GPU 模式保障流畅运行。更难得的是,LocalDream 完全开源免费,内置数十种动漫与写实风格模型,并支持导入 LoRA、SDXL 等高级自定义模型,满足从入门到进阶的各类创作需求。
软件特色
多设备推理适配:深度优化高通骁龙 NPU 加速能力,生成速度提升 30% 以上;同时兼容 CPU/GPU 推理模式,确保中低端 Android 设备也能顺畅使用,真正打破硬件门槛。
本地数据安全保障:所有绘图过程完全在设备端完成,无需上传任何文字提示或生成图像至云端,有效规避隐私泄露风险,无论是个人创作还是商业用途都安心无忧。
轻量化资源管理:安装包体积控制在 100MB 以内,占用存储空间极小;支持一键清理缓存,并可自由导入 LoRA 等自定义模型,兼顾灵活性与系统流畅性。
localdream使用指南
1、环境准备与初始化
为获得最佳体验,建议使用搭载高通骁龙 8 Gen 1 或更高版本芯片的安卓手机,以充分发挥 NPU 加速优势。
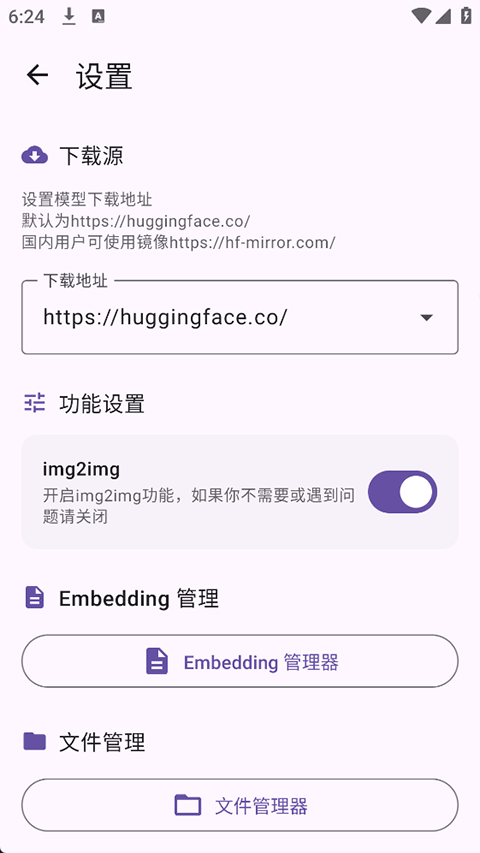
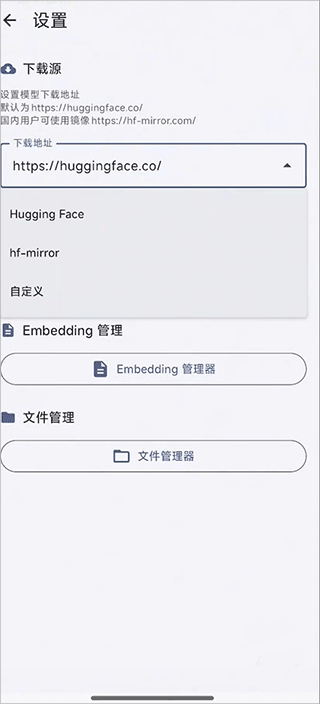
首次启动时,应用会自动下载必要的运行环境(如 Runtime 库),建议在 Wi-Fi 网络下完成初始化。国内用户可在设置界面中配置网络代理,以确保资源顺利加载。
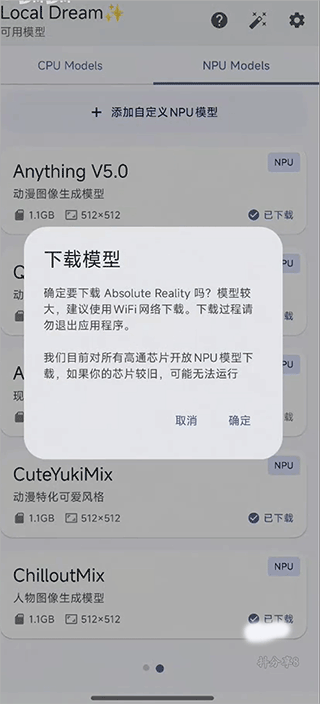
具体网络设置方式如下图所示:
2、导入模型资源
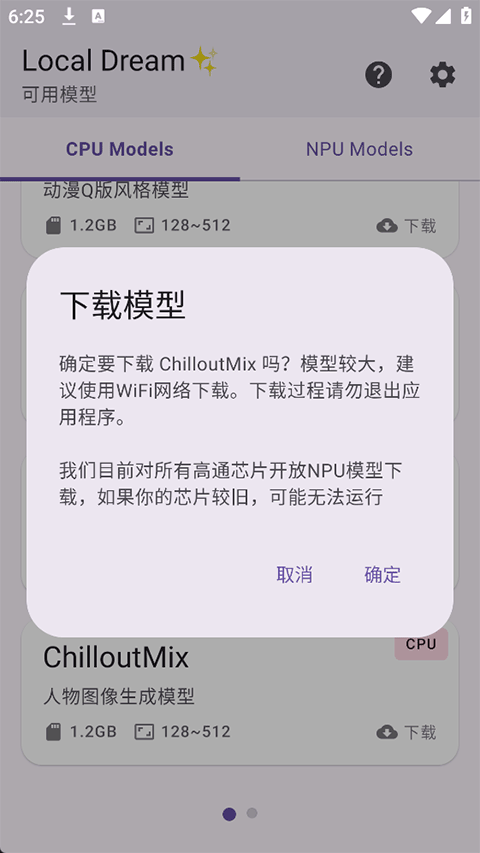
将你拥有的 .safetensors 或 .ckpt 格式模型文件放入手机存储中的 LocalDream/models 文件夹。
若使用 LoRA 或 VAE 文件,请分别放入对应的子目录(如 models/lora、models/vae),应用会自动识别并加载。
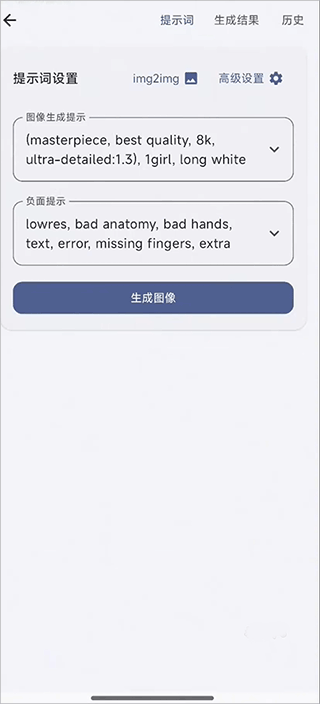
3、配置生成参数
Prompt(提示词):在输入框中详细描述你希望生成的画面内容。
参数设置:选择采样器(推荐 Euler A)、设定生成步数(通常 20–30 步)及图片比例。
硬件开关:进入设置确保开启 NPU 加速功能,这是实现极速出图的关键。
4、开始生成与预览
点击“生成图像”按钮后,进度条将实时显示处理状态。
生成完成的图片会自动保存至手机相册,支持点击查看大图,也可进行局部重绘等精细调整。
软件功能
【完全离线与极致私密】
所有 AI 运算均在本地完成,无需联网,既保护你的提示词不被外泄,也避免产生流量费用或云端排队等待。
【硬件级加速(NPU支持)】
基于 QNN SDK 深度优化高通骁龙芯片的 NPU 调用能力,在旗舰设备上实现 3–4 秒出图的惊人速度。
【完整的创作模式】
全面支持文生图(txt2img)、图生图(img2img)和局部重绘(Inpaint)三大核心功能,并内置 Euler A 等主流采样器,覆盖绝大多数创作场景。
【高度自由的模型扩展】
兼容 Stable Diffusion 1.5 主模型、LoRA 权重、Embedding 插件(如 EasyNegative),并完整支持提示词权重语法(例如 (masterpiece:1.5)),赋予你充分的创作控制权。
【内置高清画质增强】
集成 Real-ESRGAN 等先进超分算法,可一键将低分辨率生成图提升为清晰锐利的高清作品,细节表现更出色。
软件优势
1、CPU模式
在相同参数下,不同设备均可复现一致结果,适合对生成稳定性要求高的场景。
2、NPU模式
仅在搭载相同芯片组的设备上保证结果一致性,但能提供最快的推理速度。
3、GPU模式
生成结果可能与 CPU 模式存在差异,且在不同设备间略有波动,适合追求性能优先的用户。
更新日志
v2.3.1版本
1、新增欧拉A调度器,在特定提示词组合下可生成质量更优的图像。
2、修复放大页面中缓存文件未被自动清理的问题,优化存储管理效率。
应用信息
- 厂商:暂无
- 包名:Han.GJZS
- 版本:6.1
- MD5值:5d0c5ce9ca27e93b8e0f63988c8cae1e
相关版本
-
 Local Dream
2026-04-20
下载
Local Dream
2026-04-20
下载
同类热门
更多好游
-
 jmcomic3.0 新闻阅读/2025-08-08下载
jmcomic3.0 新闻阅读/2025-08-08下载 -
 甜蜜女友2 经营模拟/2026-05-08下载
甜蜜女友2 经营模拟/2026-05-08下载 -
 e站(ehviewer) 新闻阅读/2025-07-24下载
e站(ehviewer) 新闻阅读/2025-07-24下载 -
e站(ehviewer)官网版 新闻阅读/2025-08-26下载
-
jmcomic3.0mic 新闻阅读/2025-07-09下载
-
 催眠游戏汉化版 冒险解谜/2025-04-18下载
催眠游戏汉化版 冒险解谜/2025-04-18下载 -
 URJJ2.0汉化版 角色扮演/2025-04-22下载
URJJ2.0汉化版 角色扮演/2025-04-22下载 -
 荐片app 图像影音/2025-10-02下载
荐片app 图像影音/2025-10-02下载