

SPSS28
- 常用工具
- 安卓软件
- 中文
- 09月25日
- 安全监测
- 无病毒
- 无外挂


SPSS28是一款非常好用的数据分析软件,可以方便地进行数据的录入、编辑、清理和转换。支持多种数据格式的导入,如 Excel、CSV、SPSS 自身格式等,同时也能与数据库进行连接以获取数据。例如,从企业的销售数据库中导入销售数据进行分析。提供描述性统计,如均值、标准差、频数等,帮助用户快速了解数据的基本特征。比如,分析学生考试成绩的平均分、最高分、最低分等。
SPSS28怎么设置
比较分析:可以进行均值比较、方差分析、t 检验等,用于比较不同组之间的数据差异。例如,比较不同性别、不同年龄段人群的收入差异。
回归分析:包括线性回归、非线性回归等多种回归模型,可用于预测和解释变量之间的关系。比如,根据历史销售数据预测未来的销售额。
高级统计分析:有因子分析、聚类分析、生存分析等复杂的统计方法,适用于深入挖掘数据背后的潜在信息。例如,通过因子分析找出影响消费者购买行为的主要因素。
灵活的可视化功能:能够生成各种图表,如柱状图、折线图、饼图、散点图等,使数据的呈现更加直观、清晰。用户可以根据自己的需求对图表进行定制,包括颜色、字体、标签等。例如,用柱状图对比不同产品的销售情况,用散点图查看两个变量之间的关系。
可编程性与扩展性:支持使用 Python 和 R 语言进行扩展和编程,用户可以根据自己的特殊需求编写脚本,实现自动化的数据处理和分析。这对于处理大量重复性的数据操作非常有帮助。
适用场景:
学术研究:在社会学、心理学、教育学等社会科学领域,以及医学、生物学等自然科学领域的学术研究中,SPSS 28 是常用的数据分析工具。研究者可以用它来处理实验数据、调查数据等,验证研究假设,得出科学的结论。
商业分析:企业在市场调研、销售分析、客户关系管理等方面,可以利用 SPSS 28 分析市场趋势、消费者行为、销售业绩等数据,为企业的决策提供数据支持。例如,分析消费者对产品的满意度,制定针对性的营销策略。
政府和公共部门:政府机构和公共部门可以使用 SPSS 28 分析社会经济数据、人口数据、公共服务数据等,评估政策的实施效果,制定更加合理的政策和规划。比如,分析城市居民的收入水平和消费结构,制定相关的经济政策。
SPSS 28 详细攻略:
数据导入与整理:
数据导入:打开 SPSS 28 软件后,点击 “文件” 菜单中的 “打开” 或 “导入数据” 选项,选择要导入的数据文件。在导入过程中,需要根据数据的格式和特点选择相应的导入方式和参数设置。例如,如果导入 Excel 文件,需要指定工作表、数据范围等。
数据清理:检查数据中是否存在缺失值、异常值等问题。对于缺失值,可以选择删除包含缺失值的个案或变量,也可以使用均值、中位数等方法进行填充。对于异常值,可以通过绘制箱线图等方法进行识别,然后根据实际情况进行处理。
变量定义与编码:根据数据的类型和分析的需要,对变量进行定义和编码。例如,将性别变量定义为分类变量,将年龄变量定义为数值变量。对于分类变量,可以设置标签,以便在分析结果中更直观地显示。
统计分析操作:
描述性统计分析:点击 “分析” 菜单中的 “描述统计” 选项,选择要分析的变量,然后点击 “确定” 即可得到描述性统计结果,包括均值、标准差、频数等。
比较分析:
均值比较:如果要比较不同组之间的均值差异,可以点击 “分析” 菜单中的 “比较均值” 选项,选择 “独立样本 T 检验”(用于比较两组数据)或 “单因素方差分析”(用于比较多组数据),然后按照提示进行操作。例如,比较男性和女性的平均收入是否存在差异。
方差分析:在进行方差分析时,需要将因变量和自变量分别选入相应的框中,然后点击 “确定” 即可得到方差分析结果。如果方差分析的结果显著,还可以进行事后检验,以确定具体哪些组之间存在差异。
回归分析:
线性回归:点击 “分析” 菜单中的 “回归” 选项,选择 “线性”,将因变量和自变量选入相应的框中,然后点击 “确定” 即可得到线性回归模型的结果。在结果中,可以查看回归系数、R 方值、显著性水平等指标,以评估模型的拟合效果和预测能力。
非线性回归:如果数据之间的关系不是线性的,可以选择 “非线性” 回归。在非线性回归中,需要先定义模型的形式,然后将数据代入模型进行拟合。SPSS 28 提供了一些常见的非线性模型,如指数模型、对数模型等,用户也可以自定义模型。
合并文件的操作步骤
1、如果个案的不同属性位于不同的数据文件中,此时需要对文件进行合并,这种情况就是个案相同但变量不同。例如某班级学生的成绩位于不同的数据文件中,数据如图1所示,此时一个同学即为一个个案,学生的成绩即为变量,符合上述情况。

2、如何对文件进行合并呢?我们先打开数据文件1,即图示的无标题1。依次点击【数据】,【合并文件】,【添加个案】,如图2所示。

3、在弹出的窗口中有两个选项,“打开数据集”和“外部SPSS Statistics数据文件”。我们使用的是SPSS数据集,选择“打开数据集”选项,选择待合并的“无标题2.sav”,点击【继续】。

4、在弹出的窗口中,选择“变量”选项卡,指合并的内容为变量,“键变量”默认为“学号”,指以学号为键值,所有变量完成与学号的一一对应。此时包含的变量默认设置为全部科目,细心的用户会注意到,数学和英语科目的标记为*,而语文,生物,化学,物理等科目的标记为+。对于这一点SPSS给出的解释是存在于原数据集的变量标记为*,增加的数据集变量标记为+。需要注意的是,除了键变量之外,待合并的变量之间不能重名。

5、点击【确定】,SPSS将完成合并过程并在数据集1中显示合并的数据。

以上就是使用SPSS合并文件的操作步骤,在合并的过程中需要找到变量的一一对应关系,即变量的配对。如何理解变量配对,如何操作,我们将在第二小节中向大家介绍。
使用spss28如何操作回归分析?
1、以下图中的数据为例,向大家介绍如何使用SPSS进行一元线性回归分析。

2、在界面依次点击【分析】,【回归】,【线性】,进入线性回归分析功能界面。
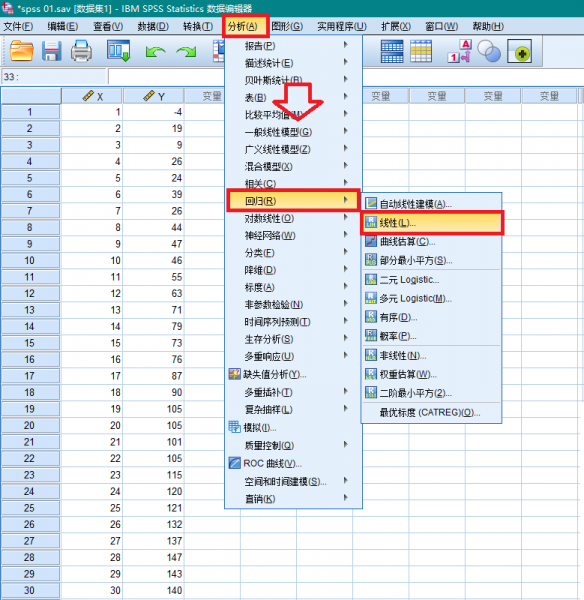
3、在线性回归分析功能界面,首先将Y指定为因变量,将X指定为自变量,然后点击【统计】按键,在弹出的窗口中,勾选“残差”项目中的“德宾-沃森”和“个案诊断”,点击【继续】。
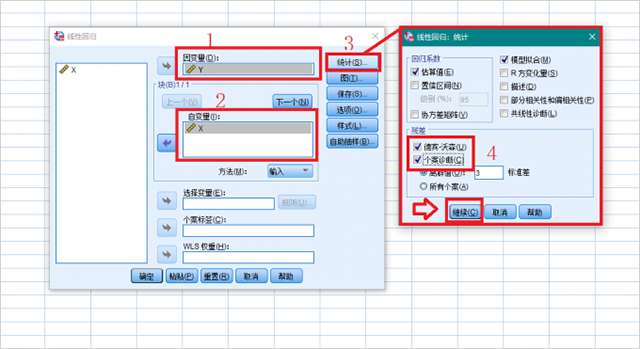
4、点击【图】按键,将*ZRESID指定为Y,将*ZPRED指定为X,在“标准化残差图”中勾选“直方图”和“正态概率图”,点击【继续】。
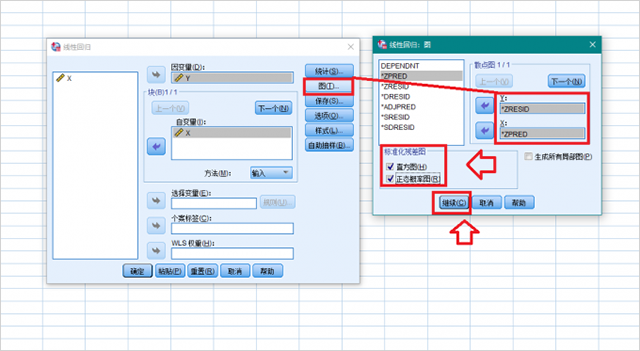
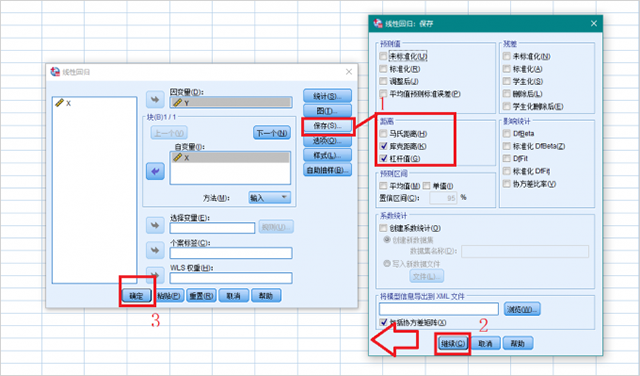
5、点击【保存】按键,在“距离”选项卡中勾选“库克距离”和“杠杆值”,点击【继续】,点击【确定】。
spss分析显著性差异如何出图?
1、数据如图下图所示,组别命名为1-5。
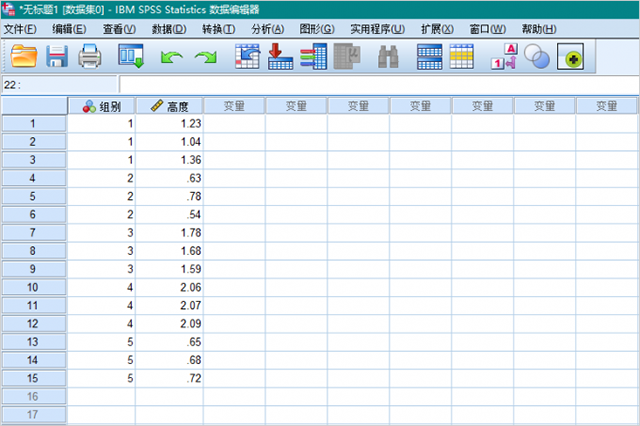
2、依次点击【分析】,【比较平均值】,【单因素ANOVA检验】。
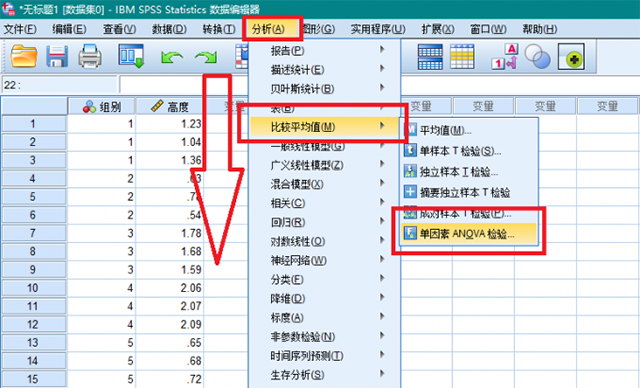
3、将高度加入“因变量列表”,将组别指定为“因子”,点击【对比】,在弹出的窗口中,勾选“多项式”选项,等级指定为四次。
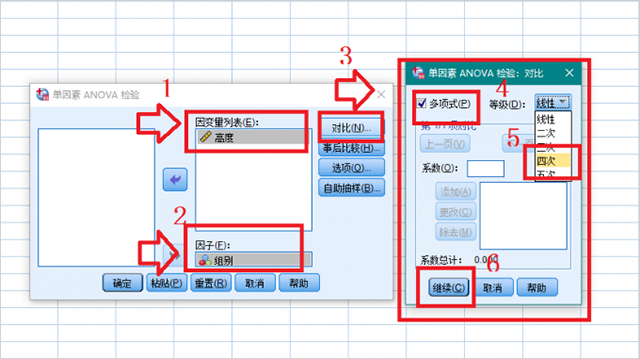
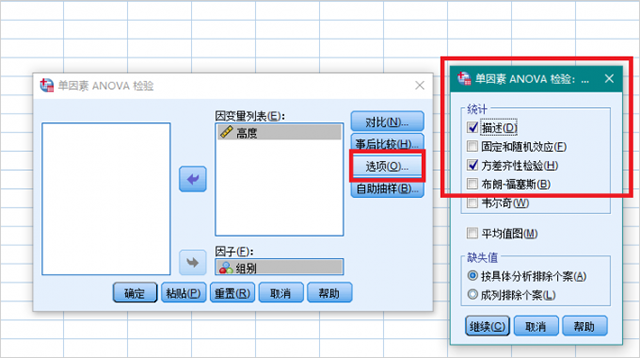
4、点击【事后比较】,在“假定等方差”中勾选“LSD”和“邓肯”两个选项,在“不假定等方差”中勾选“塔姆黑尼T2”和“邓尼特T3”两个选项,显著性水平保持默认0.05即可。点击【继续】。
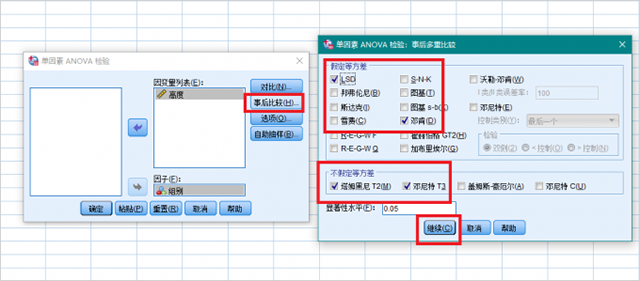
5、点击【选项】,在弹出的窗口中勾选“描述”和“方差齐性检验”,点击【继续】,点击【确定】。SPSS将进行组间的差异性分析。
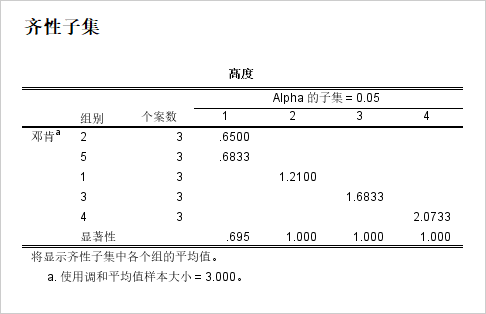
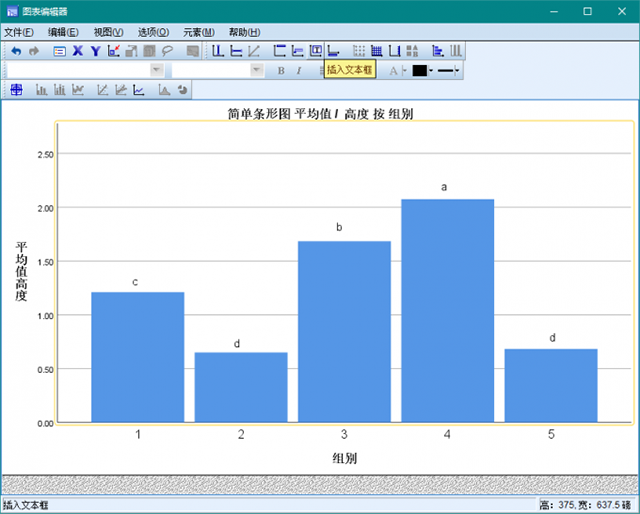
6、统计结果如图6所示,第一列代表组别,第二列代表每个组别含有的个案数,从第三列开始,每一个纵列代表一个子集,共4个子集。子集与子集之间存在显著性差异,从右下角为起点,为每个子集标注a,b,c,d,第二组和第五组之间没有显著性差异,共同标记为d。
7、作图同样可在SPSS中进行,在图7所示界面依次点击【图形】,【图表构建器】,进入绘图界面。
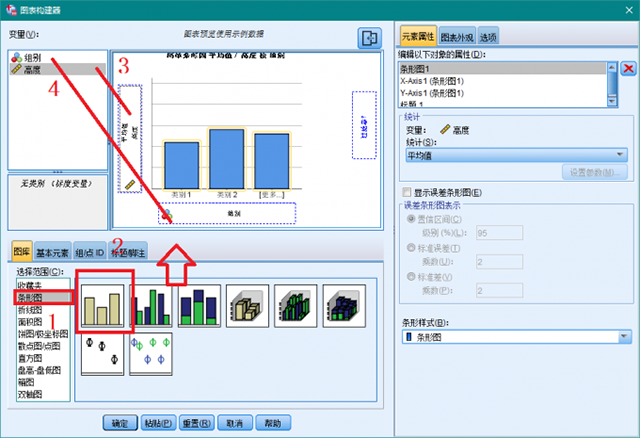
8、在图8所示界面中,在“图库”选项卡中选择条形图,然后将标记的图例拖动到预览窗口中,拖动“组别”到X轴,拖动“高度”到Y轴,点击【确定】。
9、spss将在结果查看器中输出图像,双击该图像,打开图表编辑器,如图9所示。
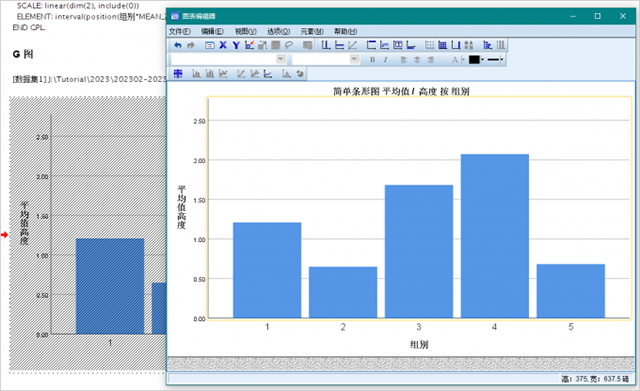
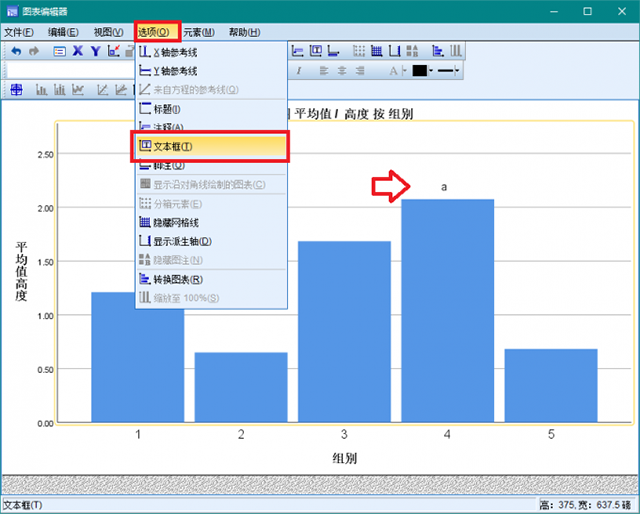
10、点击【选项】,【文本框】,插入文本框,拖动文本框至第四组处,输入a,然后按照上述对各子集的标注,依次输入b,c,d。
11、字母不同代表组别存在显著性差异,字母相同代表不存在显著性差异。
快捷键说明
New Data Editor Sheet = Alt + F + N + A
New Syntax Window = Alt + F + N + S
New Output Window = Alt + F + N + O
New Draft Output Window = Alt + F + N + R
New Script Window = Alt + F + N + C
Save = Alt + F + S or Ctrl + S
Save As = Alt + F + A
Display Data Info = Alt + F + I
Apply Data Dictionary = Alt + F + D
Cache Data = Alt + F + C
Print Data = Alt + F + P
Print Preview = Alt + F + V
Switch Server = Alt + F + W
Open Datafile = Alt + F + O + A
Open Syntax File = Alt + F + O + S
Open utput File = Alt + F + O + O
Open Script File = Alt + F + O + C
Open Other File = Alt + F + O + T
Open Database - New Query = Alt + F + B + N
Open Database - Edit Saved Query = Alt + F + B + E
Open Database - Run Saved Query = Alt + F + B + R
Open Text Data = Alt + F + R







